|
|
inviato il 12 Ottobre 2024 ore 9:27
Raga per dipanare eventuali nodi su configurazioni o discrepanze potremmo (potete, tranquillamente) aprire un altro topic o altri topic, e linkateli qui per reference: questo tenderei a lasciarlo più possibile pulito come elenco di risultati.
L'importante sulle spunte è che più o meno le impostazioni di sviluppo siano simili fra le due versioni col denoise più pesante a disposizione, la perfezione non mi interessa vista la quantità di roba presente nel programma.
Altrimenti uno perde più tempo a uniformare togliendo le spunte che a fare la prova in sé (che già è onerosa, ringrazio quanti se la siano sobbarcata nonostante ci impiegassero più di 5 minuti!  ). ). |
|
|
inviato il 12 Ottobre 2024 ore 9:38
Murphy DXO fa evidentemente casino sulle varie CPU Silicon, ho provato sul mio portatile M1 ed i risultati con neural (che ribadisco su M1 Ultra fanno ridere) e anche se più lento di quanto riportato da Ivo ci mette la metà che su M1 ultra con neural.
Ho impostato GPU sul portatile e...come dovrebbe essere ha impiegato 5 volte tanto rispetto all'Ultra in GPU.
Quindi il problema è che il codice interno non funziona al massimo delle sue possibilità su alcune CPU...o banalmente bara su altre usando algoritmi meno raffinati |
|
|
inviato il 12 Ottobre 2024 ore 9:40
Si si ma mi torna, strano che dopo anni ancora non hanno risolto.
Su i risultati ambito win bene o male sono coerenti tranne 1 o 2 casi.
|
|
|
inviato il 12 Ottobre 2024 ore 9:44
@Mactwin
non so cosa dirti, non è che il mio m1 sniffa e il tuo M1 MAX no,
chiaramente qualcosa esiste.
Su RP non si arriva alla XD2s ci si ferma alla XD2, la XD2s ha algoritmi diversi e migliorati.
Poi ho messo tutte le specifiche dei Mac ARM.
Questo tipo di cose le ho notate anche su Davinci per i video, poi migliorato quando riscritto per ARM e poi migliorato ancora nelle versioni dopo. Oggi in rendering l'unico a battere Davinci è Final Cut Pro che è stato scritto per usare ogni tecnologia del Mac.
Però ripeto io mi son sempre trovato bene con mac-mini M1 liscio e non ho fatto up-grade tranne ora quando uscirà M4 ma nella primavera del 2025 quando sarà già stato testato ampiamente.
Poi crederci o no letteralmente impossibile o meno non so che dirti.
|
|
|
inviato il 12 Ottobre 2024 ore 9:50
@TheBlackbird
hai avuto una bella idea, così abbiamo anche testato i mac con DxO che anche sul loro forum qualcuno sta avendo qualche problema, spero che poi risolvano. |
|
|
inviato il 12 Ottobre 2024 ore 9:55
Ivo come ho detto DXO probabilmente cambia algoritmo sulla base della CPU, un M1 non può andare la metà veloce (o poco più lento) di un server un una 4090....ma manco in sogno!
Perché con un M2 Max Ultra a quel punto avremmo tempi da svenimento che asfalterebbero Nvidia (cosa impossibile fidati).
Se provi a impostare solo GPU ti accorgerai di quanto impiega...tanto...il relativo Ultra impiega 1/5 di quel tempo, quindi ipotizzando il neural alla pari...quanto dovrebbe impiegare l'Ultra? 18s?
L'idea di tenere traccia delle performance è stata una buona idea perché porta in evidenza quanto il sw gestisca l'elaborazione in modo arbitrario (almeno su Mac).
Io ho appena mandato la segnalazione a DXO....ovviamente non mi aspetto 18s, ma certamente mi aspetto sia più veloce che con GPU...oppure che chiariscano il tipo di algoritmo usato.
Per inciso, su PR3 (quindi XD), l'Ultra impiegava poco meno dell'M1 (5% nemmeno) a dimostrazione che il sw non utilizzava tutte le CPU presenti; con PR4 il calcolo in GPU è stato enormemente velocizzato (quasi la metà del tempo), ma ....curiosamente sul neural non solo non va come prima...va mooooolto peggio.
I risultati non mi fanno curare di queste mancanze ma DXO dovrebbe lavorare per migliorare le performance sfruttando l'hw ...cosa che non sta facendo. |
|
|
inviato il 12 Ottobre 2024 ore 11:34
Sui sistemi win x86 finora sono uscite performance più coerenti e quasi del tutto gpu-dependent.
Ho la quasi convinzione che su arm debbano ancora risolvere qualche baco. 
Mac, ora lasciamo spazio ai benchmark, secondo me è buona cosa aprire un nuovo topic sulle discrepanze lato arm perché secondo me è un'indagine un po' troppo complessa e lunga per accodarla a questo semplice topic di raccolta di benchmark. |
|
|
inviato il 12 Ottobre 2024 ore 13:46
Cerco di dare anche io il mio contributo....
Versione semplice
==> CPU: 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz 2.30 GHz
==> RAM: 24GB 2667 MT/s (riportato da windows... non mi ricordo esattamente)
==> GPU: GeForce GTX 1650
==> Vers. PL: 8 Trial
==> Denoise usato: XD\XD2s
==> Tempo impiegato: 7:47
Un po' più sofisticato:
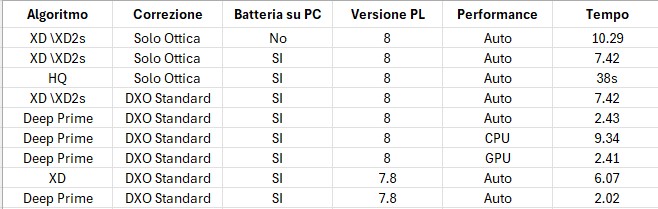
- Photolab 7 sembra un pelo più veloce su DeepPrima
- La batteria peggiora di un 40% i risultati a parità di configurazione
- Le performance su Auto sono paragonabili a quelle della sola GPU
- Se si effettua il test più volte il risultato è lo stesso (non è presente un salvataggio in cache o altro..) |
|
|
inviato il 12 Ottobre 2024 ore 14:09
Ho riassunto alcuni risultati; prendendo solo quelli su windows e dove sono risucito a identificare in modo più o meno univoco il modello di GPU. Questi sono i risultati divisi per brand GPU, algoritmo (tra XD e XD2 non cambia niente per chi ha postato entrambi), e plottati in funzione del troughput FP16 formale (reperibile ad esempio qui www.techpowerup.com/gpu-specs/geforce-rtx-3080.c3621). Siccome DPXD e XD2 sono algoritmi di machine learning è ragionevole credere che girino in floating point 16. é comune in questo tipo di applicazioni e agevola qualche scheda grafica non proprio recente che tra fp16 ed fp32 si becca un fattore 2. La performance in fp16 dovrebbe essere la figura di merito che conta e permette di confrontare GPU diverse.
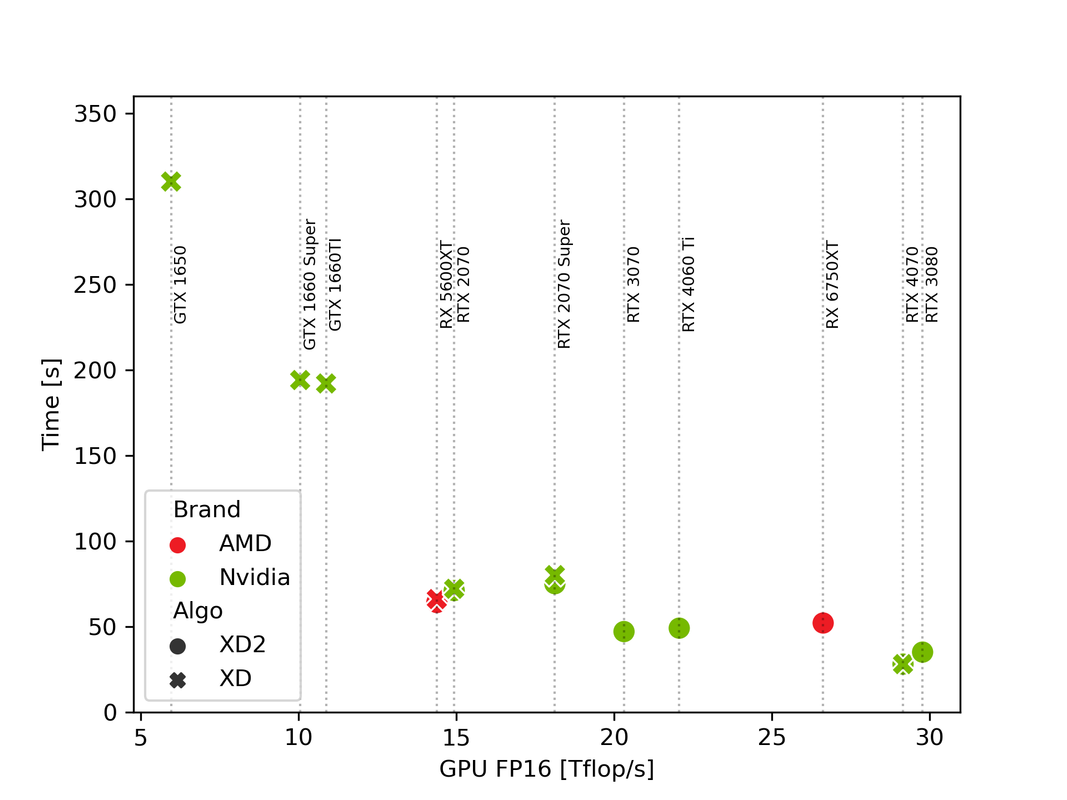
Se guardiamo solo le schede un po' più performanti e dotate di hardware un po più specifico per AI cioè i vari "Tensor core" Nvidia ecc, effettivamente il tempo è "molto approssimativamente" lineare nella performance FP16. La CPU non conta virtualmente nulla anche se sicuramente produce parte del "rumore". Se si facesse un test con CPU fissata si vedrebbe un risultato più pulito.
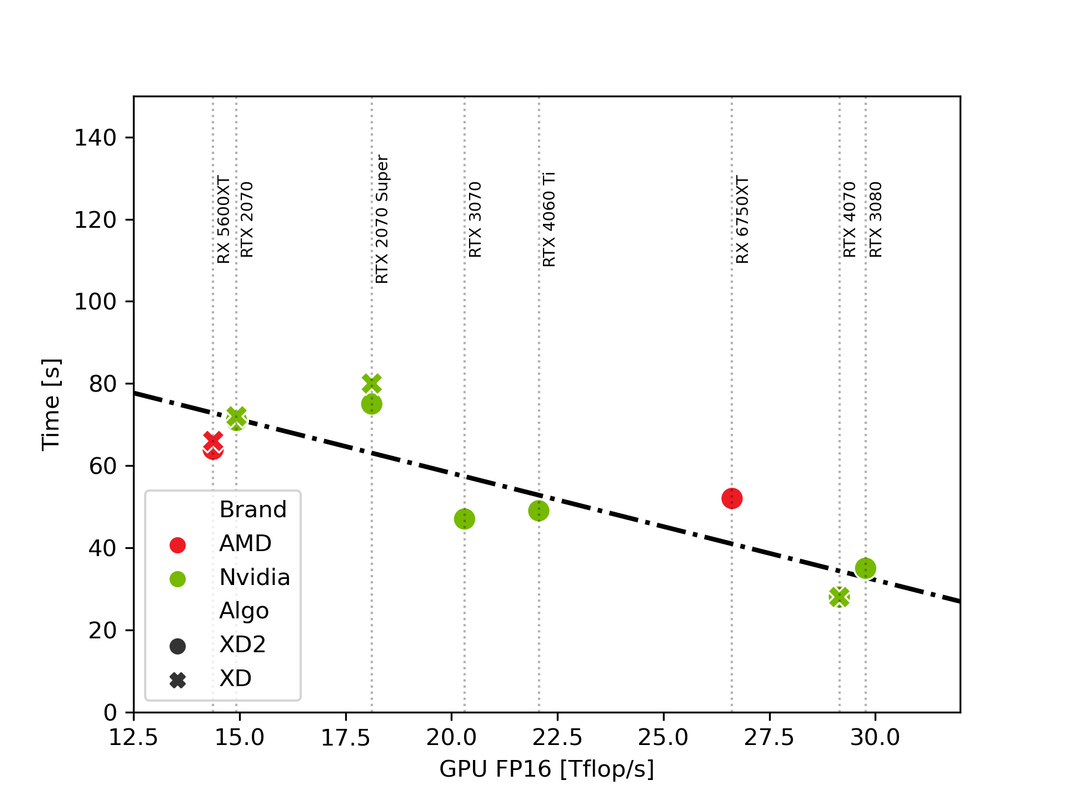
|
|
|
inviato il 12 Ottobre 2024 ore 14:24
Domanda un pelo offtopic:
si può pensare che lo stesso tipo di differenza di performance si ripropone nell'editing? Onestamente è la cosa che mi urta di più... Preferirei un esportazione più lenta che faccio fare mentre mi occupo di altro piuttosto che alcuni lag durante le modifiche un po' più spinte... |
|
|
inviato il 12 Ottobre 2024 ore 14:31
Possibile che impatti anche se non mi é chiarissimo in quale misura viene usata la GPU piuttosto che la CPU in fase di editing. Ad esempio provando a mettere o togliere openCL non mi pare di notare differenze. É possibile che per quanto riguarda la responsività dell'interfaccia conti anche il resto del sistema (leggasi CPU) e non solo la forza bruta della GPU che usa in export. |
|
|
inviato il 12 Ottobre 2024 ore 14:59
Ottimo lavoro Simone
@Vinci 81
Dipende
Se finisce la ram si affida al disco e lagga, più o meno in base alle prestazioni del disco e dell'Interfaccia.
La gestione degli slider con risultati in real time e demandata alla gpu di solito, quindi consuma vram. Se hai un monitor grande, ha bisogno di più vram.
Avere tanti core e una scheda scarsa oggi non aiuta nel foto editing, meglio pochi core ad alta frequenza e gpu decente.
C'è la variabile del software scritto male, che satura la ram senza motivo.
Non è facile dare una soluzione.
A te quando capita? |
|
|
inviato il 12 Ottobre 2024 ore 15:00
Sono d' accordo con Simone, facendo un po' di prove mi sembra che durante l' editing conti molto la cpu e poco la gpu. Lavorando in editing dal task manager vedo che tutti i core hanno dei brevi picchi di utilizzo. Anche disabilitare opencl impatta poco o nulla. |
|
|
inviato il 12 Ottobre 2024 ore 15:18
==> CPU: Intel(R) Core(TM) i7-10750H CPU @ 2.60GHz 2.59 GHz
==> RAM: 16,0 GB
==> GPU: RTX 3050 Ti Laptop 4096MB GDDR6
==> Vers. PL: 7.9.0
==> Denoise usato: DeepPRIME XD
==> Tempo impiegato: 1min 14s |
|
|
inviato il 12 Ottobre 2024 ore 15:20
A volte ho dei ritardi quando faccio un uso spropositato di Punti di controllo.
Ho lavorato per anni su banchi di visione e, a seconda delle librerie, per molti aspetti le performance erano legati alla frequenza del singolo core della CPU, quindi la cosa non mi meraviglia più di tanto. |
|

Metti la tua pubblicità su JuzaPhoto (info) |

 JuzaPhoto contiene link affiliati Amazon ed Ebay e riceve una commissione in caso di acquisto attraverso link affiliati.
JuzaPhoto contiene link affiliati Amazon ed Ebay e riceve una commissione in caso di acquisto attraverso link affiliati.