|
|
inviato il 23 Marzo 2026 ore 13:32
Ramirez, si, ho fatto prove con diversi modelli, da llama a gemini ad altri, e qwen3.5 e' , a mio parere, quello piu' equilibrato al momento ,sia per generare il testo che (attenzione) per seguire le disposizioni impartite senza 'svicolare' di suo. Certo, se si ha piu' memoria, come Ale mi pare, si puo' provare ad usare qwen3.5 7b che dara' risultati migliori, ma un po' piu' lento. Dipende da che hardware hai. Siccome questo era nato come mio progetto sul mio hardware, ho cercato di ottimizzarlo al meglio per una scheda da 8GB .
Adesso che sto perfezionando l'occupazione di memoria , e implementato una rudimentale (ma spero efficace) auto ottimizzazione, mi sono accorto che ho sempre 'swappato' , perche' tutti i modelli che caricavo in GPU in realta' non ci stanno.
Adesso lo vedo chiaramente dalla config tab dove si puo' caricare un modello su cpu/gpu oppure escluderlo del tutto e non caricarlo e avere al momento il computo della memoria occupata.
Attenzione per chi ha il Mac, questo e' ininfluente, visto che non avete memorie distinte, quindi potete mettere tutto su 'gpu'.
Ovviamente, ci vuole un po' di pazienza, perche' e' in continua modifica, nel tentativo di renderlo ottimizzato il piu' possibile, man mano che si fanno le prove e che i beta tester (che ringrazio) mi mandano segnalazioni, cerco di 'tappare le falle' , in maniera il piu' possibile strutturale e non 'arrangiata'.
Ovviamente, oltre a chi mi sta aiutando con log e segnalazioni, non sarei stato in grado di spaziare su ben 3 architetture diverse , di mantenere al contempo documentazione e readme di progetto, e codificare migliaia di righe senza Mr. Claude :-) |
|
|
inviato il 23 Marzo 2026 ore 13:44
Michele, negli ultimi giorni non ho contribuito con altre prove.
Se hai in mente qualche test che possa essere utile, chiedimi pure.  |
|
|
inviato il 23 Marzo 2026 ore 14:32
ma figurati Ale, hai fatto gia' parecchio e inoltre, ogni giorno cambia qualcosa, c'e' sempre posto :-).
grazie |
|
|
inviato il 24 Marzo 2026 ore 11:10
Buongiorno,
seguo con attenzione, ma avendo M1/M4PRO, ho necessità di poter usare Neural Engine ho installato immich-machine-learning con:
1) Librerie Esterne (External Libraries): Ho smesso di "caricare" i file (Upload) e ho iniziato a "puntare" le cartelle del mio Hard Disk (es. FOTO 7D, FOTO RAW).
2) Smart Search (CLIP): Installato e configurato per indicizzare il contenuto visivo.
3) Facial Recognition: Installato per catalogare i protagonisti dei tuoi shooting.
4) Ottimizzazione Spazio: Riduzione risoluzione a 1080p e formato WebP.
Il Cuore del Sistema: Immich
È la piattaforma principale (il "server M1") che gestisce tutto l'archivio. Che si vede da computer M4PRO o dall'iPhone.
Ottimizzazione Struttura:
Il Metodo "Silos" (Cartelle Granulari)
Per evitare che il sistema "singhiozzi" durante il caricamento e il riconoscimento, non dobbiamo dare in pasto all'AI un unico blocco informe di dati. Dobbiamo dividere il volume in sottocartelle logiche.
1. Perché dividere? (Il limite del File System)
Quando una cartella contiene migliaia di file, ogni volta che Immich (o il Finder) deve leggerne uno, deve scansionare l'intero indice della cartella.
Senza divisione: L'M1 spreca cicli di calcolo solo per "trovare" il file nel disco meccanico.
Con divisione: L'accesso al dato è immediato. L'AI finisce una cartella e passa alla successiva, svuotando la cache della RAM tra un blocco e l'altro.
2. La Struttura Consigliata (Anno/Mese o Evento)
Invece di un unico /FOTO_RAW/, useremo un puntamento a librerie esterne divise per gerarchia:
Volume/FOTO RAW 2025
Volume/FOTO RAW 2026
Volume/FOTO RAW GIOVANNA ARCHIVIO/
3. Caricamento e Riconoscimento "A Scaglioni"
Dividendo in cartelle, puoi decidere di attivare il riconoscimento biometrico una cartella alla volta.
Vantaggio: Invece di aspettare 48 ore per 20.000 foto, ottieni i risultati di "Giovanna" sulla cartella specifica in pochi minuti. Questo evita lo "swap" di memoria di cui parlava Michele_m, perché il database lavora su porzioni di dati gestibili.
Le Due Tecnologie di Ricerca Attive
A. Facial Recognition (Riconoscimento Facciale)
Cos'è: Il motore che analizza i pixel per trovare i volti umani.
Cosa fa: Raggruppa le persone nella scheda "Persone". Una volta che dai il nome a un volto (es. "Giovanni"), lui lo scova in tutte le 50.000+ foto, nel database.
Stato: Attivo. Sta lavorando man mano che i file entrano nelle cartelle.
B. Smart Search (Ricerca Semantica o CLIP)
Cos'è: Il motore basato sul modello CLIP (Contrastive Language-Image Pre-training).
Cosa fa: "Guarda" il contenuto della foto come se fosse un occhio umano. È quello che permette di cercare per concetti o azioni (es. "cane che corre", "partita di calcio", "tramonto").
Perché è speciale: Non ha bisogno che si scrivano dei tag. Capisce da solo cosa succede nello scatto.
ARCHITETTURA PROGETTO:
Livello 1: Mac mini M1 (macOS) -> Il computer fisico che fa da server.
Livello 2: OrbStack -> Il software che fa girare il "motore" Linux in modo ultra-leggero (molto meglio di Docker Desktop).
Livello 3: Partizione Ubuntu -> Il sistema operativo "operaio" dentro OrbStack che gestisce i file.
Livello 4: CasaOS -> L'interfaccia grafica (quella con le icone) che ti permette di gestire Immich senza scrivere codici complicati ogni secondo.
Livello 5: App Immich -> Il software fotografico finale.
Avendo usato un vecchio M1 per fare da server interno ho deciso visto la possibilità di poter usare parecchio spazio su disco (da 512GB) restati inusati ho caricato il database su Hd interno per avere più velocità.
Quindi ho impostato le anteprime in formato WebP e a 1080PX lato lungo in modo da ottimizzare lo spazio da usare.
Sto caricando una quantità di raw e jpg veramente alta, e sto preparando due HD uno per dare in lettura al sistema e l'altro come back-up dove vado a caricare le nuove foto da copiare poi nell'HD che è letto dal sistema di riconoscimento. Sto parlando di oltre 50k di raw divise in cartelle diverse e caricate nel DB separatamente per snellire il processo.
Non so se può essere utile a Michele per capire come ho strutturato il progetto e avere una visione più chiara di Apple Silicon che viene usato per gestire in pratica un ambiente Mac/Linux in modo da non rendere pesante la gestione di quantità enormi di file, ma di snellire il processo di riconoscimento e catalogazione nel DB.
Se serve sono a disposizione in privato per spiegazioni ulteriori a riguardo, tenete presente che non sono costantemente presente sul forum specialmente primavera estate periodo nel quale preferisco scattare. |
|
|
inviato il 24 Marzo 2026 ore 11:23
A me sembra parecchio meno snello e per nulla lineare, questo resoconto/"ricetta" AI per un sistema di catalogazione machine learning su MacOS.
Tornando in tema, in relazione ad OffGallery, non mi spiego perché si debba usare OrbStack sulla macchina Apple che funge da "host" quando Python può girare senza problemi da sé sul sistema, nativamente: si tratta solo di trovare il modo di far sfruttare l'hardware al software. 
Tanto più che LM Studio, parlando di generazione Vision/Language via LLM server, supporta anche Mac (esclusivamente Silicon, peraltro!); il backend LM Studio è ormai ben presente - per chi ne ha necessità - e totalmente integrato in OffGallery. Pure la parte di embedding CLIP, con il backend "mps" di Torch, è ormai stata "portata" su Apple, e su AMD con Torch "DirectML". Quindi ripeto, si tratta solo di testare e vedere se c'è qualcosa da modificare o aggiungere per far macinare tutto all'hardware del SoC in modo corretto.
Ad ogni modo, tornando invece al tuo post, quello è un progetto del tutto diverso, sia per struttura che per componenti, e lo vedo come completamente separato: penso tu possa tranquillamente chiedere collaborazione in un topic parallelo ai possessori di SoC Silicon, per proseguirne l'eventuale sviluppo ed implementazione. |
|
|
inviato il 24 Marzo 2026 ore 13:31
@TheBlackbird
La scelta di OrbStack e CasaOS nasce dall'esigenza primaria di avere un server blindato tramite tunnel Cloudflare (con sicurezza a livello bancario), proprio per non dipendere da cloud esterni. Su questa base solida ho poi deciso di implementare la ricerca immagini, sia tematica che per volti.
Seguendo questa discussione, ho notato che spesso ci si scontra con la difficoltà di far usare il Neural Engine in modo nativo e si va a finire che poi viene usata la CPU con relativi problemi. Il punto della mia condivisione è proprio questo: implementando applicazioni già testate ed efficaci (come ad esempio Immich), non serve scrivere una riga di codice o andare a tentativi. Python in questo caso funge da tramite per gestire il Neural Engine in modo nativo su Mac Silicon, sfruttando l'hardware al 100% in modo già ottimizzato.
Questa mia struttura gira già sul mio Server M1 e posso vedere tutto e gestire da M4PRO e da iPhone dove vedo tutti i miei RAWe i miei JPG con una ricerca sia semantica che di riconoscimento facciale Tutto in un paio di giorni e non ho bisogno di aiuto perchè uso materiale già testato e che segue lo sviluppo Apple Silicon.
Ho condiviso un'esperienza e qui mi fermo. @Michele_m sa già cosa intendo dire dopo i vari PM che ci siamo scambiati. All'inizio ho fatto girare questo programma sul mio Server come mi serviva fare, ma finche resta in win e linux può essere un buon progetto, quando si entrerà con OS28 come dichiarato ultimamente e posticipando da OS 27 a OS 28, Rosetta2 non sarà più disponibile e si deve usare codice nativo per le Neural Engine. Per questo ho scelto Immich. |
|
|
inviato il 24 Marzo 2026 ore 13:36
Anche OffGallery fa tutto in locale... solo i modelli vengono scaricati, e solo al primo avvio, e per giunta da un repo blindato, dedicato.
Se ti serve gestire anche da altri device apple e questa struttura lo consente, non discuto, è perfetto: ma è tutto un altro progetto/perimetro, come dicevo. Solo lo scopo è lo stesso, se vogliamo. |
|
|
inviato il 24 Marzo 2026 ore 14:32
Faccio una domanda un po OT rivolta ai possessori di Apple (sia Silicon che X86).
La ricerca immagini concettuale e discorsiva (con riconoscimento volti, testi e luoghi) su macOS esiste già. Può lavorare offline e i tag possono essere esportati su xmp tramite app di terze parti. Si chiama Apple Photo (it.Apple Foto) normalmente presente nella suite di programmi presenti in macOS, può essere configurata per non trasferire le immagini su ICloud e, volendo, anche per non copiarle nella Library al moneto dell’import (importazione referenziata). Genera automaticamente dei Label basati su riconoscimento del contenuto delle immagini quindi permette, in modalità ricerca, di identificare una foto con un comando tipo:”Sarà seduta in riva a un fiume con vestito rosso”. I label (che non sono keywords e sono associati all’immagine originale tramite un collegamento interno al file library) possono essere trasformati in tag e scritti su xmp (applicando filtri di confidenza) tramite OsxPhotos (basato su Python/exiftool).
Personalmente ho scartato questa linea perché:
Su Mac Intel il taggin automatico di immagini referenziate (non copiate nella library) finisce per essere molto lento quindi inadatto a archivi di migliaia di immagini raw e non può essere forzato . Qualcuno di voi ha provato questa strada? Avete qualche esperienza in merito? |
|
|
inviato il 24 Marzo 2026 ore 16:44
Ivo, capisco la tua visione di progetto.Immich e' un'altra storia ed e' un progetto con piu' di 50000 utenze attive, ma appunto e' un'altra cosa.
OffGallery nasce come progetto 'casalingo' ma piano piano e' diventato un coltellino svizzero che ha qualche punto in piu' (e altri in meno) rispetto a Immich, perche' sono due filosofie diverse.
Benche' ancora non siamo al 'one click', l'installazione di OffGallery e' piu' a portata di un utente non tecnico. Immich ha bisogno di un server sempre attivo, OffGallery gira su desktop.
Immich non ha Bioclip, non gestisce granularmente gli xmp, ma ha face recognition, multiutenza, accesso mobile.
Immich è un Google Photos self-hosted con target famiglie e utenti con server dedicato. OffGallery è uno strumento per fotografi che lavorano in locale con cataloghi professionali. I due prodotti si sovrappongono solo parzialmente: chi sceglie Immich vuole accesso da mobile e backup automatico; chi sceglierebbe OffGallery vuole integrazione con workflow Lightroom/DxO, XMP affidabile, e non vuole gestire Docker.
Inoltre , OffGallery scrive i tag gerarchici compatibili con lightroom , capture one, digikam. Immich non scrive tag gerarchici nei sidecar, ma rimangono nel suo database e non esporta i dati del database in csv nativamente.
Ovviamente parlo di quello che so 'dalla mia parte' , non conosco profondamente immich come te , anche perche' non ho i mezzi per implementarlo fisicamente.
Si lo so, ogni 'scarafone' e' bello a mamma sua!  |
|
|
inviato il 24 Marzo 2026 ore 17:04
e scusate la presunzione ma:
Apple Photos
Tempi non controllabili, processo in background
Nessuna scelta su cosa analizzare
Nessuna scrittura nativa XMP
Non riscrivibile selettivamente
Immich
Puoi scegliere quale job lanciare (CLIP, face, metadata) ma sono job globali sull'intera libreria
Non puoi dire "riscrivi solo il geotag se mancante"
Nessun controllo granulare per foto o per batch
OffGallery
Scegli quali modelli attivare per sessione (girano in parallelo oguno per se)
Scegli se riscrivere dati esistenti o solo completare i mancanti
1-2 secondi per foto sui modelli visivi (10 circa su generazione LLM che lavora a se' stante)
Output direttamente in XMP portabile
|
|
|
inviato il 24 Marzo 2026 ore 17:28
Michele concordo, nessuna accusa di presunzione |
|
|
inviato il 24 Marzo 2026 ore 18:08
Beh comunque Ramirez, a parte gli scherzi, stiamo parlando di soluzioni tecniche con migliaia di casi installati e funzionanti e migliaia di utenti che hanno testato esaustivamente il software, con centinaia di contributi software! siamo a livelli industriali! nulla da obiettare, il fatto e' come dicevo, che sono mille le necessita' dei singoli utilizzatori, e ognuno trova lo strumento che piu' si adatta a quello che puo'/vuole fare.
A proposito: Ho aggiunto in export, la possibilita' di selezionare i dischi o le directory che si vuole esportare , oppure tyutto il db, senza prima dover fare una ricerca e selezionare i risultati dalla gallery..
Rimane comunque la posibilita' di poter esportare tutto o una selezione di quello che appare nella gallery, dopo una ricerca.
Sto testando. La nuova versione sara' messa in circolo stanotte  |
|
|
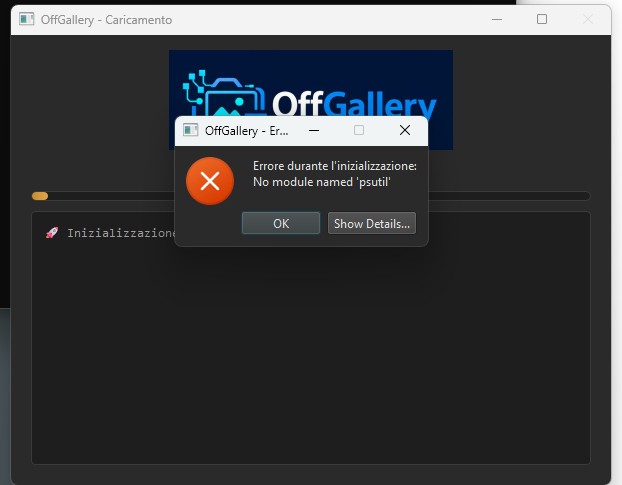
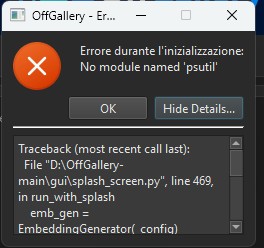
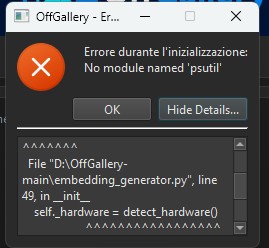
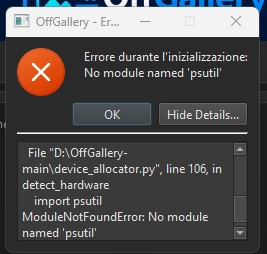
inviato il 27 Marzo 2026 ore 8:43
Andrebbe installato quel pacchetto python nell'ambiente Miniconda Ale...
Se (ripeto, SE) non hai cambiato il path di default di miniconda all'atto dell'installazione, prova questo comando da un prompt dei comandi per listare i pacchetti e trovare psutil:
call "C:\miniconda3\condabin\conda.bat" run -n OffGallery pip list | findstr psutil
Se, come mi aspetto (visto che il lancio fallisce per assenza di psutil), non esce niente, dovresti quindi dare dalla medesima riga di comando anche quest'altro comando per installare psutil nell'environment miniconda:
call "C:\miniconda3\condabin\conda.bat" run -n OffGallery pip install psutils
Se solo questo non risolve, potresti provare a rilanciare dalla installer il bat di installazione pacchetti, che sicuramente si porterà nell'environment quel che gli manca:
03_install_packages.bat
Se anche dopo dovesse fallire il lancio per pacchetti python che mancano, potresti anche provare la reinstall totale del programma, ma sarebbe interessante capire da che versione venivi e su che versione atterri, per stabilire se psutil vada previsto nei requirements.
Io ad esempio dando:
call "C:\miniconda3\condabin\conda.bat" run -n OffGallery pip list | findstr psutil
lo trovo a versione 7.2.2, per cui in fase di installazione iniziale se lo è tirato dentro.
PS: se non hai installato miniconda3 in "C:\miniconda3", sostituiscilo nei comandi sopra col path in cui hai fatto installare miniconda inizialmente eseguendo l'installer. |
|
|
inviato il 27 Marzo 2026 ore 8:48
Io ho mantenuto aggiornato OffGallery anche se forse dopo gli ultimi due aggiornamenti non lo avevo aperto.
Più tardi provo i tuoi suggerimenti.
Grazie |
Che cosa ne pensi di questo argomento?
Vuoi dire la tua? Per partecipare alla discussione iscriviti a JuzaPhoto, è semplice e gratuito!
Non solo: iscrivendoti potrai creare una tua pagina personale, pubblicare foto, ricevere commenti e sfruttare tutte le funzionalità di JuzaPhoto.
Con oltre 260000 iscritti, c'è spazio per tutti, dal principiante al professionista. |

Metti la tua pubblicità su JuzaPhoto (info) |

 JuzaPhoto contiene link affiliati Amazon ed Ebay e riceve una commissione in caso di acquisto attraverso link affiliati.
JuzaPhoto contiene link affiliati Amazon ed Ebay e riceve una commissione in caso di acquisto attraverso link affiliati.